Īsumā par to, kas notiek pašā sākumā, kad tiek kompilēts vai interpretēts kods, specifiski runājot par Priedi:
Programmēšanas valodu implementācijas lielākoties daļās divās daļās: interpretatori un kompilatori. Tie atšķirās ar to, kā tiek izpildīts kods, savukārt pirmās izpildes stadijas abiem ir vienādas un par to arī turpmākais raksts. Pēc šādiem principiem darbojās absolūts vairums kompilatoru un interpretatoru pasaulē. Šī noteikti nav pamācība, bet varu ieteikt e-grāmatu “Crafting Interpreters”
Satura rādītājs
Kā saprast programmas kodu
Pirms ķerties klāt kodam, varētu paskatīties uz matemātiskām izteiksmēm, jo tas arī ir pieraksts ar instrukcijām, kas jāveic lai nonāktu pie rezultāta.
1+2*3
Ņemot vērā matemātisko darbību secību, vispirms veicam reizināšanu un tad saskaitīšanu. Šīs izteiksmes izpildi varētu attēlot grafikā.
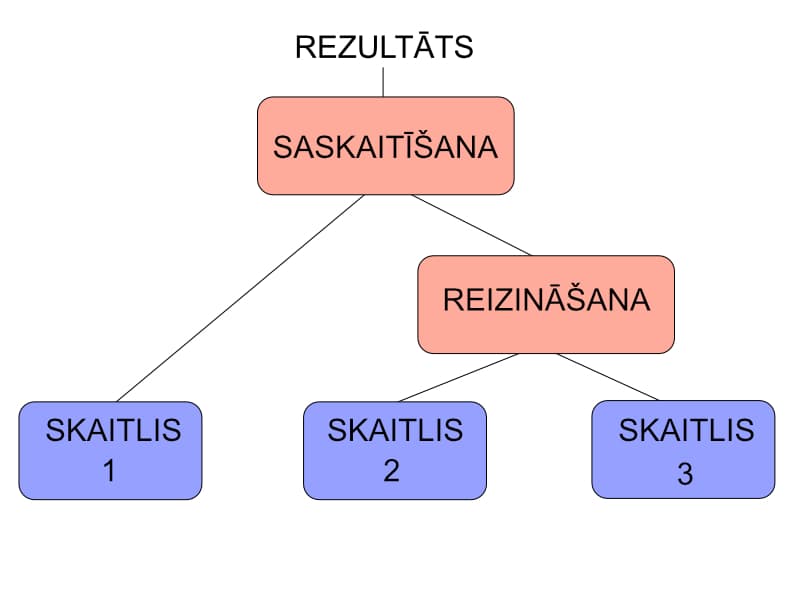
Šo grafiku sauc par Abstraktās Sintakses Koku un tas tiek ģenerēts, lai tiktu vaļā no cilvēka rakstītā, koda. Tam nosaukums dots tāds, jo tas ir neatkarīgs no programmēšanas valodas sintakses(pieraksta veida). Divas valodas ar atšķirīgiem instrukciju pierakstiem ģenerēs vienādus abstraktās sintakses kokus. Kompilatora uzdevums ir likt datoram saprast instrukcijas, ko ir rakstījis cilvēks un šis ir pirmais posms tajā procesā - abstrahēties no cilvēka rakstītā, vienkārši lasāmā, koda
Turpinot ar kodu…
a = 3-2
print(1+2*a)
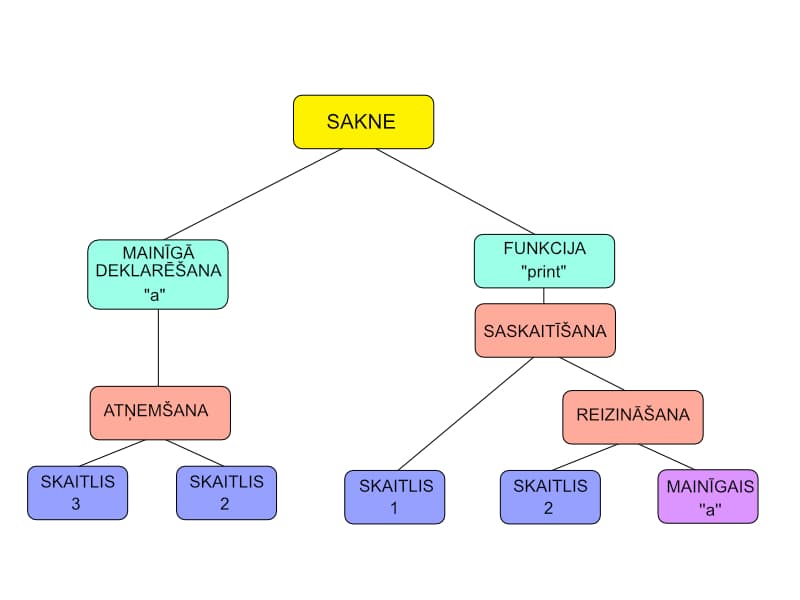
Te svarīgi norādīt, ka koks tiek apskatīts no kreisās puses, uz labo. Tas ir svarīgi piem. atņemšanas darbībai un programmas saknei, kur ir svarīga secība kādā tiek izpildītas instrukcijas
Kā izaudzēt Abstraktās Sintakses Koku
Pirmais solis ir saprast kādi simboli veido kodu un kāda ir to nozīme tajā
a = 3-2
print(1+2*a)
Varētu uzrakstīt šādā sarakstā:
MAINĪGĀ NOSAUKUMS "a"
ZĪME =
SKAITLIS 3
ZĪME -
SKAITLIS 2
JAUNA RINDA
FUNKCIJAS NOSAUKUMS "print"
ATVEROŠĀ IEKAVA
SKAITLIS 1
ZĪME +
SKAITLIS 2
ZĪME *
MAINĪGĀ NOSAUKUMS "a"
AIZVEROŠĀ IEKAVA
Šo sarakstu ģenerēt no koda ir Leksera uzdevums
Lekseris
Augstāk minētos simbolus turpmāk sauksim par tokeniem.
Lekseris sastāv no cikla, kas iet cauri kodam un veido augstāk minēto sarakstu. Atkal iedomājamies vienkāršu matemātisku izteiksmi.
2+1*3
Izveidot lekseri, kas var saprast šādu izteiksmi, ir diezgan elementāri tāpēc, ka katrs tokens ir viena rakstzīme tekstā, tāpēc viss, kas vajadzīgs ir cikls, kas iet cauri tekstam un pārbauda kādai rakstzīmei tas uzdūries virsū.
input = "2+1*3"
for character in input:
if character == "+":
print("ZĪME +")
elif character == "*":
print("ZĪME *")
elif character.is_digit():
print("CIPARS " + character)
else:
print("Neatpazīts simbols")
Izpildot augstāko Python kodu iegūstam tokenu sarakstu
CIPARS 2
ZĪME +
CIPARS 1
ZĪME *
CIPARS 3
Problēmas sākās, kad parādās tokeni, kas ir garāki par vienu rakstzīmi piem. daudzciparu skaitļi
2+1*34
Izlaižot šo izteiksmi caur esošo lekseri, iegūstam šādu rezultātu:
CIPARS 2
ZĪME +
CIPARS 1
ZĪME *
CIPARS 3
CIPARS 4
Tas tāpēc, ka mūsu lekseris ir ļoti tuvredzīgs. Tas ierauga ciparu un uzreiz met ārā jaunu tokenu. Šajā piemērā, protams, ir iespēja šim sarakstam izskriet cauri vēlreiz un, ieraugot vairākus blakus esošus ciparus, savienot tos skaitlī, bet glītāk būtu šo problēmu atrisināt jau lekserī. Lai to izdarītu būtu vajadzība paskatīties kas seko pēc pašreizējā tokena.
input = "2+1*3"
while True:
character = get_next_character()
if character == "+":
print("ZĪME +")
elif character == "*":
print("ZĪME *")
elif character.is_digit():
digits = []
digits.append(character)
while True:
if see_next_character().is_digit():
digits.append(get_next_character())
else:
break
print("SKAITLIS " + digits_to_number(cipari))
else:
print("Neatpazīts simbols")
Šoreiz ieraugot ciparu, pārbaudām nākamo rakstzīmi. Ja tā arī ir cipars, tātad esam sastapuši daudzciparu skaitli un ejam uz priekšu par rakstzīmju sarakstu kamēr sastopam rakstzīmi, kas nav cipars. Tad visus savāktos ciparus savienojam skaitlī un sviežam ārā.
Šajā kodā ir divas funkcijas ar būtisku atšķirību.
get_next_character() atgriež nākamo rakstzīmi, kā arī noņem to no rakstzīmju saraksta. Tādējādi mēs to apstrādājam tagad.
see_next_character() atgriež nākamo rakstzīmi, bet to atstāj tālākai apskatīšanai.
Funkcija digits_to_number() apvieno ciparu sarakstu skaitlī
Tagad iegūstam pareizo tokenu sarakstu:
SKAITLIS 2
ZĪME +
SKAITLIS 1
ZĪME *
SKAITLIS 34
Apgrieztais poļu pieraksts
Apgrieztais poļu pieraksts ir matemātisku izteiksmju pieraksta veids un to varētu arī uzskatīt par alternatīvu abstraktajam sintakses kokam. Tajā tiek pierakstīti abi darbības skaitļi un tikai pēc tam darbības zīme.
2 + 1 kļūst par 2 1 +
3 − 4 + 5 kļūst par 3 4 − 5 +
Izpildīt izteiksmi apgrieztajā poļu pierakstā var, nevienā brīdi neredzot visu izteiksmi kopumā, tikai lineāri ejot cauri izteiksmei, pa vienam simbolam. Nav arī nekas jāzina par darbību secību.
Lai izpildītu šo pierakstu nepieciešams saraksts ar skaitliskām vērtībām - steks. Steka īpatnība ir tāda, ka pievienot skaitļus var tikai tā augšā un noņemt arī var tikai pašu augšējo vērtību.
Kā izpildīt darbību 3 4 − 5 +:
- Ieraugam skaitli 3 - ieliekam to steka augšpusē
- Ieraugam skaitli 4 - ieliekam to steka augšpusē
- Ieraugot atņemšanas zīmi, noņemam no steka augšas divas vērtības uz izpildām atņemšanas darbību. Rezultātu uzliekam atpakaļ steka augšpusē.
- Ieraugam skaitli 5 - ieliekam to steka augšpusē
- Ieraugot saskaitīšanas zīmi, noņemam no steka augšas divas vērtības uz izpildām saskaitīšanas darbību. Rezultātu uzliekam atpakaļ steka augšpusē.
- Programmas beigas - noņemam augšējo vērtību no steka un tas arī ir rezultāts
Kā izpildīt darbību 3 4 - sin:
- Ieraugam skaitli 3 - ieliekam to steka augšpusē
- Ieraugam skaitli 4 - ieliekam to steka augšpusē
- Ieraugot atņemšanas zīmi, noņemam no steka augšas divas vērtības uz izpildām atņemšanas darbību. Rezultātu uzliekam atpakaļ steka augšpusē.
- Ieraugam funkciju, kurai nepieciešams viens arguments, tāpēc noņemam no steka augšējo vērtību un izsaucam sīnusa funkciju ar to. Funkcijas rezultātu uzliekam steka augšpusē.
- Programmas beigas - noņemam augšējo vērtību no steka un tas arī ir rezultāts
Pārseris
Pārseris ir nākamā stadija pēc leksera. Tas izmanto iepriekš ģenerēto tokenu sarakstu, lai ģenerētu abstrakto sintakses koku, vai piem. apgriezto poļu pierakstu.
”Vilcienu šķirošanas” algoritms
Reāli izmantojami pārseri var būt diezgan sarežģīti un netiek rakstīti manuāli, bet gan izmantojot pārsera ģeneratorus. Arī priede tā dara, bet ir pāris vienkārši algoritmi, kas var ģenerēt apgriezto poļu pierakstu no tokenu saraksta. Tam ir dots tāds nosaukums, jo tas atgādina vilcienu šķirošanas staciju
“Vilcienu šķirošanas” algoritmā tiek izmantoti divi steki. Viens uzglabā skaitliskas vērtības, otrs uzglabā darbību zīmes un citus operatorus.
Kā 3 − 4 + 5 pārveidot apgrieztajā poļu pierakstā:
- Ieraugam skaitli 3 - ieliekam to vērtību steka augšpusē
- Ieraugot atņemšanas zīmi - ieliektam to operatoru stekā
- Ieraugam skaitli 4 - ieliekam to vērtību steka augšpusē
- Ieraugam saskaitīšanas zīmi - steka augšpusē jau ir operators ar tādu pašu prioritāti ( - ), tāpēc to noņemam un pievienojam vērtību stekam, bet operatoru stekam pievienojam jauno saskaitīšanas zīmi
- Ieraugam skaitli 5 - ieliekam to vērtību steka augšpusē
- Programmas beigas - visus operatorus no operatoru steka pievienojam vērtību stekam. Tad vērtību stekā atradīsies izteiksme apgrieztajā poļu pierakstā.
3 4 − 5 +
Leksera + Parsera ģenerators
Lekseri un pārseri bieži netiek rakstīti ar roku, arī Priedes gadījumā. Tā vietā izmantojot leksera + pārsera ģeneratorus. Priede izmanto atvērtā koda projektu Hime. Tas nolasa kodu un ģenerē abstraktās sintakses koku pēc noteiktas gramatikas. Katram gramatikas punktam ir nosaukums un pēc -> simbola seko simboli, kas to sastāda, | svītrai kalpojot par vai operatoru. Galā noslēdzoties ar semikolu.
exp_atom -> NUMBER
| '(' exp ')';
reizdal -> exp_atom
| reizdal '*' exp_atom
| reizdal '/' exp_atom;
plusminus -> reizdal
| plusminus '+' reizdal
| plusminus '-' reizdal;
exp -> plusminus;
Šī gramatika norāda, ka reizināšanas un dalīšanas darbības ir kā apakšsadaļa saskaitīšanas un atņemšanas darbībām. Tādējādi tiek nodrošināta pareiza matemātisko darbību secība.
Šis gramatikas pieraksts tiek izmantots, lai Hime ģenerētu lekseri un parseri, kas atrodas binārā formā. Tālāk Rust kods izmanto šos bināros failus, kopā ar Hime rust bibliotēku, lai ģenerētu abstrakto sintakses koku Priedes programmēšanas valodas kodam.
Un tālāk sākās jautrā daļa.